Deciphering the Motive: Why and How We Chose Table Partitioning
Setting the Scene
Our core platform setup consists of a Django application on top of a PostgreSQL database. The initiative stemmed from the recognition that a critical table within our application, known as “resources_translation” that stored the translation data in the Transifex application was significantly impacting the performance due to its continuous growth in size and usage. The proposed solution was to implement table partitioning on the database level to optimize the performance of CRUD operations on this specific table.
The main challenge was twofold:
- Develop and execute a migration plan to transition the existing heavily utilized table to its partitioned counterpart, considering that most access to it occurred through the Django ORM.
- Conduct experiments to gather data-driven insights into the potential impact of this endeavor.
Hypothesis
Initially, we hypothesized that dividing the table would offer numerous benefits, such as:
- Reduced I/O reads
- Decreased cache misses
- Lower memory usage
Our hypothesis centered on the notion that partitioning the table would amplify data locality, thereby mitigating the need for disk I/O operations. By utilizing the organization_id as the partition key, we anticipated that queries pinpointing specific subsets of the data would experience more streamlined access to pertinent information. Consequently, this optimization could lead to swifter query execution times and an overall augmentation in system performance.
To delve further into this concept, let’s consider the typical page size, which is commonly set at 8KB. This implies that a single page may encompass multiple relevant rows. Hence, if an organization’s data is confined within a single partition, it is highly likely that we would require access to fewer pages during query execution.
Furthermore, the principle of data locality extends to indexes, and the indexes of partitioned tables are expected to be smaller in size. We envisaged that smaller index sizes would correlate with faster index scans and diminished memory overhead.
Lastly, we anticipated that the improved data locality and reduced index sizes would enhance data caching mechanisms by optimizing the utilization of memory resources. With data being stored more efficiently and index sizes minimized, there would be a higher likelihood of frequently accessed data and index pages residing in the cache, whether within PostgreSQL’s shared buffers or the operating system’s file system cache. This heightened cache efficiency would lead to a greater proportion of queries being satisfied from memory, further diminishing the reliance on disk I/O operations and contributing to overall performance gains.
Proof of Concept and Benchmarks
Next, we proceeded to validate our hypothesis through a series of experiments and benchmarking.
We established a staging environment and implemented our partitioning solution to prototype its functionality. It’s important to note that while experimental results can provide valuable insights, they may not perfectly reflect real-world production scenarios. Nonetheless, they guide us in making informed decisions about our system.
Our benchmarking efforts initially focused on database reads, particularly in the Editor module, which extensively queries the tables using various methods. Some queries returned over 200,000 rows, necessitating swift retrieval. This module was also frequently flagged by customers for its sluggish performance, especially when using filters like text which are not supported by indexes.
To assess the impact of partitioning on read performance, we duplicated the resources_translation table with varying partition numbers: 128, 256, and 512. Through rigorous benchmarking, we determined that 256 partitions offered optimal performance in our specific use cases. However, to ensure future scalability, we opted for 512 partitions, which exhibited similar performance characteristics. It’s essential to acknowledge that direct comparisons between the initial and partitioned tables may not always be straightforward due to differences in query plans. Nevertheless, overall, our initial hypothesis appeared to hold true, especially for the outliers. Text filtering would now perform much better.
Transitioning to our next experiment, we investigated the effects of partitioning on write operations. Contrary to our initial expectations, we discovered a significant impact on write performance. To understand the influence of triggers and indexes on write operations, we conducted tests by gradually removing them from two tables with identical configurations. Surprisingly, we observed that writes were notably faster on tables with smaller indexes in partitioned setups. This optimization resulted in a remarkable 50% performance improvement in our staging environment.
Behind the Scenes: Implementing Postgres Table Partitioning
Data Integrity and Population
As outlined earlier, our objective was to create a new partitioned table mirroring the structure and data of the original table, “resources_translation”. The aim was to maintain all existing data while ensuring constant updates and synchronization with new data. However, before proceeding, ensuring data integrity was paramount.
Firstly, we focused on two crucial preparatory steps:
- Populating the original and referencing tables with the partition key, “organization_id”.
- Ensuring data integrity by enforcing “organization_id” as not null in the original table.
The initial step ensured that the original table would be updated with the necessary “organization_id” for successful syncing with the partitioned table. Additionally, we extended this process to include tables with foreign keys on the resources_traslation table, ensuring consistency across the database and achieving performant lookups on the resources_translation table.
The second step was vital to prevent any data inconsistency in the partitioned table. Despite efforts to manage updates and data population programmatically, implementing a database-level constraint was necessary to fully safeguard data integrity.
It’s worth noting that our initial research suggested a two-step approach to adding the not null constraint aimed at minimizing downtime. However, practical implementation revealed unexpected challenges. Contrary to expectations, Postgres imposed a full table lock during the process, significantly delaying subsequent operations. Consequently, we had to execute the update within a scheduled downtime window to mitigate disruptions effectively.
Data Synchronization
Prior to executing any CRUD operations on the partitioned table, it was imperative to populate it with existing data from the original table and maintain synchronization. This ensured that all subsequent CRUD actions performed on the original table would be mirrored in the partitioned table.
To accomplish this, we implemented a three-step strategy:
- Population of the partitioned table with existing data from the original table.
- Addition of necessary triggers on the original table to ensure that subsequent operations are propagated to the partitioned table.
- Re-execution of the population process to address any missed data between the initial population and the implementation of triggers.
Retrieving Data
The Editor allows users to access both source and translation data, performing various operations such as text matching, status filtering, date filtering, and sorting.
It’s important to highlight that prior to deploying changes to production, our staging environment, operating on a database different from production, along with a custom testing environment utilizing a production replica, provided us with initial insights into the potential benefits of partitioning. However, due to differences in database configurations and usage patterns between staging and production, any comparison was inherently flawed.
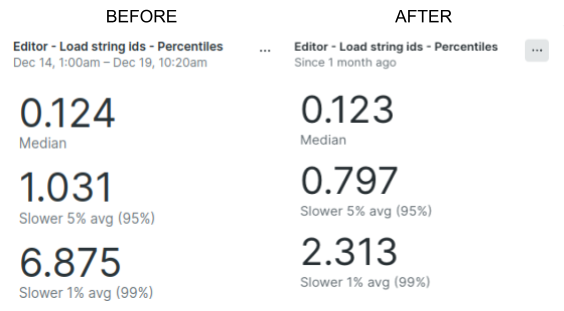
Upon updating the codebase to optimize all Editor queries to utilize the partition key, and following successful passage through our QA process, we began to observe improvements in the Editor’s performance metrics. The median loading time remained largely unaffected. However, significant improvements were noted in the slower percentiles:
- A notable decrease from 1.031s to 0.797s was observed in the 5% slower reads.
- The most significant improvement was witnessed in the extreme 1% slower cases, with a remarkable 66% decrease in loading time.
In addition to the broader performance metrics, a notable enhancement was observed in text search functionality. Our implementation relies on regular expression pattern matching in PostgreSQL, which can be resource-intensive since it cannot be supported well by indexes. This approach often necessitates scanning through the entire table, leading to potential performance bottlenecks. However, by harnessing the benefits of data segmentation and reduced scan overhead offered by partitioning, we successfully achieved significant performance improvements in this area.
Triggers Management
The initial “resources_translation” table featured numerous PostgreSQL triggers responsible for forwarding data modifications to other tables. Subsequently, the task at hand was to transfer these triggers to the partitioned table. This transition necessitated atomicity, ensuring that the operation occurred seamlessly alongside the trigger responsible for migrating data from the original to the partitioned table. To achieve this, we employed Postgres transaction blocks, allowing us to bundle the steps of trigger creation on the partitioned table and trigger deletion from the original table into single operations. These operations were designed to be applied as a cohesive unit or not at all, thereby preserving the integrity of the database structure.

C(R)UD
The concluding phase of this endeavor involved migrating the rest of the CRUD operations apart from reads to the partitioned table. With everything properly set up and having conducted experiments in our staging environment that bolstered our confidence in data integrity and performance enhancements, the remaining tasks became straightforward. We simply needed to utilize the correct Django models and ensure that all operations on the partitioned table incorporated the partition key to target specific partitions rather than all of them. Naturally, this required meticulous QA testing to ensure no remnants were left utilizing the original table.
Confronting Limitations: Django’s Absence in Postgres Table Partitioning
Composite Foreign Keys
The transition to a partitioned PostgreSQL table also affected the corresponding Django model. A significant challenge arose due to Django’s lack of support for composite foreign keys, especially when including the partition key for optimal performance in accessing the partitioned table. As Django did not offer a solution for this, we had to implement the necessary foreign key constraints directly at the database level. This constraint was essential not only for foreign keys referencing the partitioned table but also for foreign keys on tables referenced by the partitioned table.
Cascading Deletions
On the same area of foreign keys and Django handling, we realized that even when on_delete is set to CASCADE in Django, this is not depicted on the database foreign key constraint (ON DELETE CASCADE in PostgreSQL), but is rather handled internally by Django. The problem is that the deletions generated by Django do not include the partition key and thus result in queries with poor performance due to accessing all the partitions. For this reason, we chose to leave Django out of the equation by:
- Preventing Django from managing the cascade of referenced object deletions by setting on_delete=NOTHING instead of CASCADE.
- Implementing a foreign key constraint at the database level with a composite key that included the partition key and also managed the cascade of deletions.

Migrations on Partitioned Tables
Django lacks native support for migrations on partitioned tables. To address this limitation, we opted to manage migrations using raw SQL and leverage Django’s state_operations. This ensures that the project state remains updated, allowing the migration autodetector to recognize the model’s current state. However, it’s important to note that this approach shifts the responsibility of managing migrations for the specific table entirely to the developers.
Partition Key Everywhere
To ensure optimal performance, any access to a partitioned table must include the partition key. Since Django lacks built-in support for partitioning and is unaware of this requirement, we enhanced the model manager with queryset extensions to achieve two objectives:
- Raise an error whenever a query is made on the model without using the partition key.
- During unit tests, conduct a thorough analysis of the queryset to ensure that any query on the partitioned table does not scan more than one partition. This operation is more resource-intensive and relies on analyzing the query’s plan.
Co-Authors: